
AI Video Generator
What is phenaki.video?
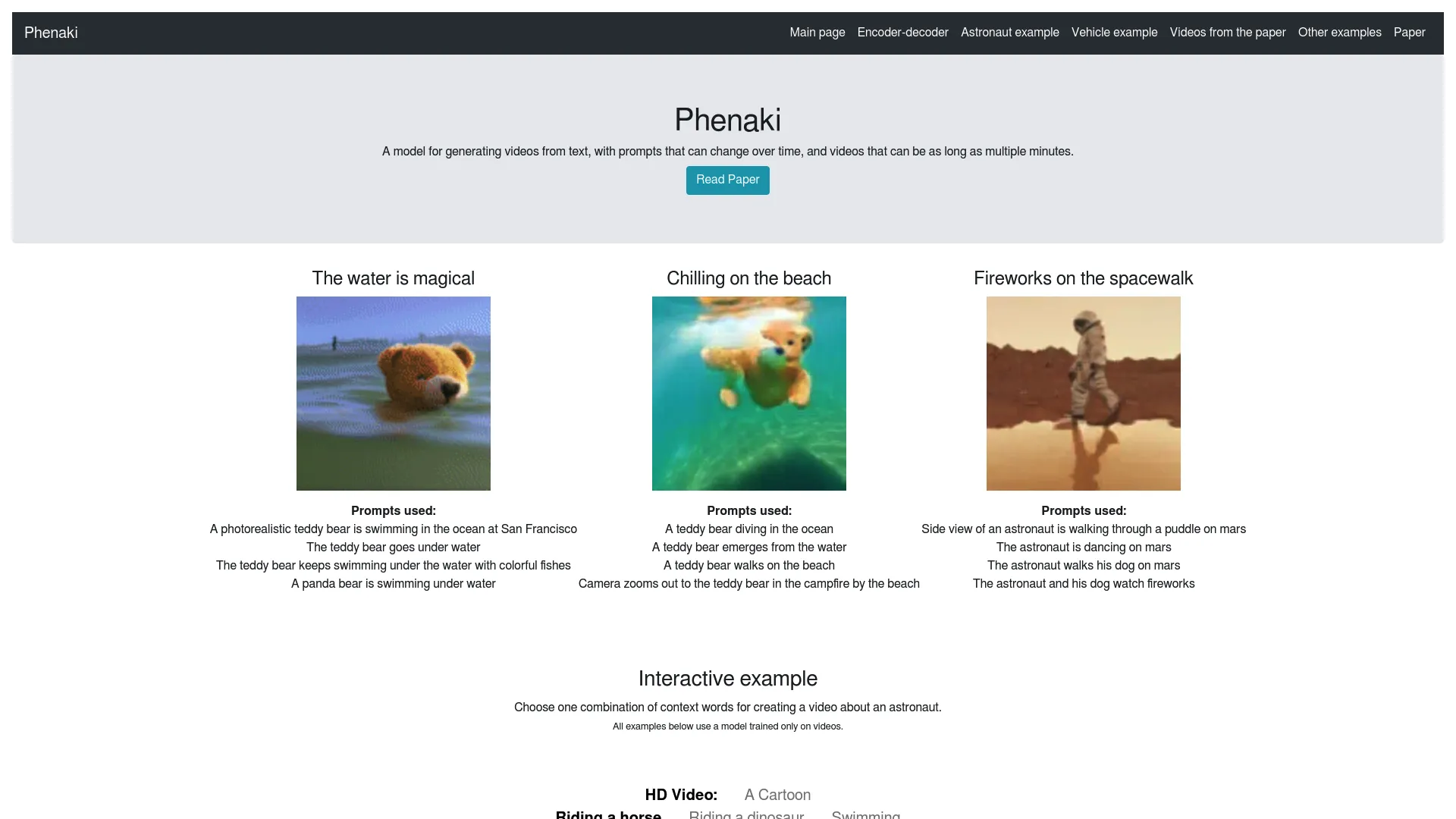
Phenaki is a video generation model designed by Google Research. It utilizes a causal model to learn video representation, compressing videos into discrete embeddings or tokens through a tokenizer capable of handling variable-length videos. With Phenaki, users can generate videos from text prompts, which can evolve over time, resulting in videos lasting multiple minutes. The model can generate videos based on open-domain sequences of prompts or stories. Additionally, it has the capability to produce video content from a single still image and a prompt. Phenaki represents an impressive advancement in AI technology, showcasing realistic video synthesis capabilities.
How does phenaki.video work?
Phenaki, developed by Google Research, is a video generation model that operates by converting text prompts into videos, accommodating prompts that may evolve over time. Videos generated by Phenaki can extend to multiple minutes in duration. The model employs a causal learning framework to compress videos into discrete embeddings or tokens, facilitated by a tokenizer capable of handling variable-length videos. Phenaki can create videos of arbitrary length based on open-domain sequences of prompts, including time-variable text or narratives. Moreover, it possesses the ability to generate videos from both a still image and a prompt. Notably, Phenaki stands out as an exceptional demonstration of realistic video synthesis, leveraging cutting-edge AI technology.
How accurate are the videos generated by phenaki.video?
Phenaki, developed by Google Research, is a pioneering model designed for video generation from text prompts, accommodating prompts that evolve over time and resulting in videos spanning multiple minutes. It employs a causal model for learning video representation, compressing videos into discrete embeddings or tokens using a specialized tokenizer capable of handling variable-length videos. Phenaki can produce videos of arbitrary length based on open-domain sequences of prompts, such as time-variable text or narratives, and can also generate video content from a single still image and a prompt.
In their research paper, Phenaki's video encoder-decoder system surpassed all existing per-frame baselines in terms of spatio-temporal quality and token count per video. Their study also highlighted the effectiveness of joint training on a vast corpus of image-text pairs and a smaller set of video-text examples, leading to generalization capabilities beyond those found in video datasets alone. Phenaki represents a notable example of realistic video synthesis achieved through state-of-the-art AI technology.
What are the benefits of phenaki.video?
Phenaki offers several notable benefits:
Realistic Video Synthesis: Phenaki can synthesize realistic videos from textual prompt sequences, overcoming challenges such as high computational costs, variable video lengths, and limited availability of high-quality text-video data.
Arbitrary Video Length Generation: It has the capability to generate videos of arbitrary lengths based on open-domain sequences of prompts, including time-variable text or narratives. This represents a pioneering exploration into generating videos from time-variable prompts, as highlighted in the relevant research.
Image-Based Video Generation: Phenaki extends creative possibilities by generating video content from a single still image and a prompt, showcasing versatility in content creation.
How much does phenaki.video cost?
The cost associated with using Phenaki for generating videos from text is not explicitly outlined in available resources. Google Research, the developers of Phenaki, may offer it as part of a research initiative or a service, with potential associated costs depending on usage and project scope. For the most accurate and up-to-date information on pricing, if any, it is advisable to consult the official Phenaki website or reach out to Google Research directly.
How does Phenaki generate videos from text prompts?
Phenaki generates videos from text prompts by employing a causal model that learns video representation through a specialized tokenizer. This tokenizer compresses videos into discrete tokens, allowing it to handle videos of variable lengths. When a text prompt is provided, Phenaki uses a bidirectional masked transformer conditioned on pre-computed text tokens to generate corresponding video tokens. These tokens are then de-tokenized to produce the actual video. Phenaki's ability to handle prompts that change over time enables it to create videos that span multiple minutes, showcasing realistic video synthesis.
What is unique about the video encoder-decoder system in Phenaki?
The video encoder-decoder system in Phenaki is unique because it outperforms all existing per-frame baselines in terms of spatio-temporal quality and the number of tokens per video. It utilizes a new causal model for learning video representation that allows it to compress video into a small representation of discrete tokens. This capability enables Phenaki to generate videos of variable lengths, accommodating sequences of prompts or narratives that change over time. The joint training on a large corpus of image-text pairs and a smaller number of video-text examples further enhances its generalization ability, making it a leading model in video synthesis.
Can Phenaki generate videos from a still image and a prompt?
Yes, Phenaki can generate videos from a still image and a prompt. This process involves using the initial frame as input, along with the accompanying textual prompt. The model then leverages its learning framework to generate video sequences that extend from the given image, creating continuous motion and storytelling. This capability of Phenaki exemplifies its versatility in content creation, allowing users to creatively extend narratives from static images into dynamic video experiences.

-2%20(1).webp)



.webp)



.webp)



















