HeliconeAI
AI Usage Tracker
Track AI usage effortlessly with HeliconeAI. Gain insights on usage and costs for language models.
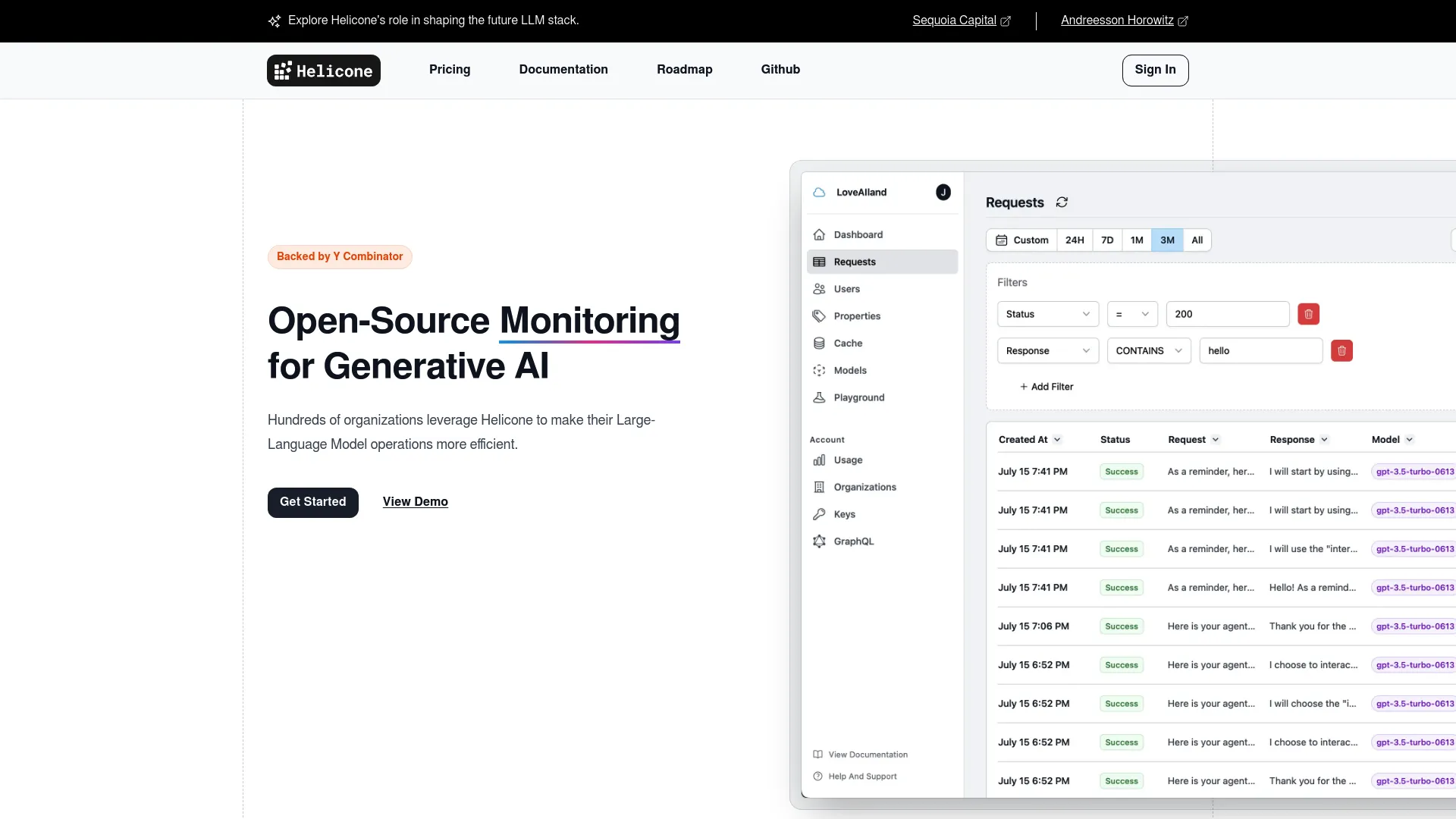
What does HeliconeAI do?
How many models are supported and how can I switch providers?
Helicone provides access to 100+ models through a single SDK. You can switch providers by changing the model name in your OpenAI SDK configuration—no code rewrites required. For example, you can use a model name like gpt-4o-mini to switch providers, and Helicone supports models from providers such as OpenAI, Claude, Gemini, DeepSeek, and more (including 100+ models from providers like Mistral, Groq, Together AI, AWS Bedrock, Azure, and others).
What integrations are supported by Helicone for seamless AI development?
Helicone integrates with major AI platforms and tooling, including OpenAI, Anthropic, Azure, LiteLLM, Anyscale, Together AI, OpenRouter, and Other. It also supports popular development environments and languages, such as TypeScript, Python, and cURL, with usage in Node.js, Python, LangChain, and LangChainJS.
How does Helicone improve LLM observability?
Helicone provides robust observability through logging and monitoring of request data (latency, costs, outcomes), instant analytics and dashboards, and the ability to filter, segment, and analyze requests in real time. It also offers user metrics and custom properties for labeling, along with high reliability (99.99% uptime) and low-latency data handling via Cloudflare Workers.
How do I get started with Helicone in my project?
- Sign up for a free account (No credit card required; 7-day free trial).
- Review the Quick Start docs.
- Integrate by pointing your OpenAI client to Helicone’s gateway (for example, use baseURL https://ai-gateway.helicone.ai).
- Explore the 100+ models and tools available (Prompts, dashboards, etc.).
- Get community support through Discord and other channels as needed.
How much does Helicone cost and is there a free trial?
Helicone uses a usage-based pricing model and offers a 7-day free trial with no credit card required. For detailed pricing information, you can consult the Pricing page or contact Helicone directly for a tailored quote.
Which runtimes and languages does Helicone support?
Helicone provides integrations and examples for TypeScript, Python, and cURL. It supports common development environments and libraries, including Node.js, Python, LangChain, and LangChainJS, enabling you to work in the languages and ecosystems you prefer.
Where can I find docs, pricing, and community resources?
You can access:
- Docs (Quick Start and in-depth guides)
- Pricing
- Community (Discord)
- Blog content and changelog
- Terms and Privacy pages
You can also connect with Helicone via social and support channels (Twitter, LinkedIn, Discord, Email).