LocalAI
AI Model Management Tool
Unlock the power of AI with LocalAI, the ultimate AI model management tool. AI Model Management made simple.
What does LocalAI do?
What is LocalAI and what does it do?
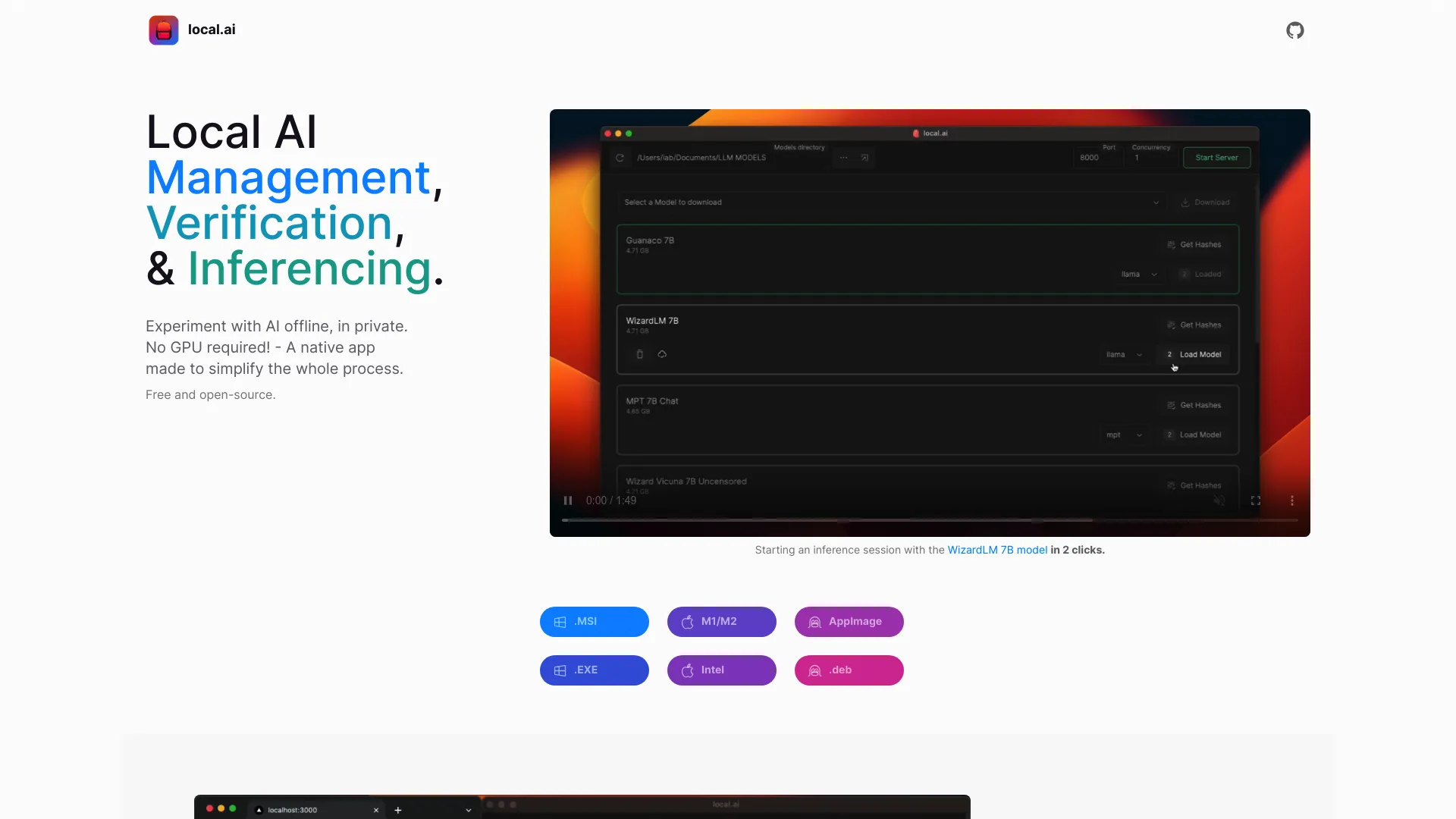
LocalAI is a free, open-source native app for local AI model management, verification, and offline inferencing. It lets you experiment with AI models privately and offline, with CPU-based inference (no GPU required). It emphasizes memory efficiency and cross-platform support, and includes features for model integrity checks, centralized model directories, and local inferencing servers. Upcoming features include GPU inferencing and expanded model management.
Is LocalAI free and open-source, and under what license?
Yes. LocalAI is free and open-source. The source code is licensed under GPLv3.
What platforms and installation options does LocalAI support?
LocalAI supports Windows (MSI and EXE installers), macOS (native Apple Silicon/M1/M2 and Intel builds), and Linux (AppImage and .deb packages). The app is designed to run natively on these platforms with a memory-efficient Rust backend.
Do I need a GPU to run LocalAI?
No. LocalAI runs AI models offline using CPU inferencing. GPU inferencing is planned for upcoming features.
What quantization options does LocalAI support?
LocalAI supports GGML quantization options including q4, 5.1, 8, and f16 for efficient CPU inferencing.
How does LocalAI ensure the integrity of downloaded AI models?
LocalAI provides robust integrity verification using digest computation (BLAKE3 and SHA256). It includes a Known-good model API and a quick BLAKE3 check to ensure only legitimate models are used. Digest verification and model information are presented to help confirm model authenticity.
What is the Known-good model API?
The Known-good model API is a feature designed to help ensure that only verified, legitimate models are used, supporting the model integrity workflow alongside digest checks.
How does LocalAI manage and organize models?
You can keep track of all AI models in a single centralized location and pick any directory to store them. Model management is directory-agnostic, providing flexible organization.
What are the model download features?
LocalAI offers a resumable, concurrent downloader and usage-based sorting to help manage and prioritize downloaded models efficiently.
What is the Model Info Card?
The Model Info Card provides details about each model (in the context of integrity verification and model metadata), supporting quick reference and verification alongside digest and known-good checks.
How can I run a local inference server with LocalAI?
You can start a local streaming server for AI inferencing in 2 clicks: load a model, then start the server. Features include a streaming server, a quick inference UI, writes to .mdx, adjustable inference parameters, and a remote vocabulary. There are upcoming enhancements like Server Management and endpoints for audio and image processing.
What are the upcoming features planned for LocalAI?
Upcoming features include:
- GPU Inferencing
- Parallel session
- Model Management
- Nested directory
- Custom Sorting and Searching
- Digest Verification enhancements
- Model Explorer
- Model Search
- Model Recommendation
- Server Management
- Audio and image endpoints (/audio, /image)
How memory-efficient is LocalAI?
LocalAI is designed to be memory-efficient, with builds that are under 10 MB on Mac M2, Windows, and Linux .deb distributions.
How does LocalAI handle offline operation and resource allocation?
LocalAI runs AI models offline, preserving privacy. It uses CPU inferencing and dynamically adapts to available CPU threads to optimize performance. GGML quantization further enhances efficiency for local execution.