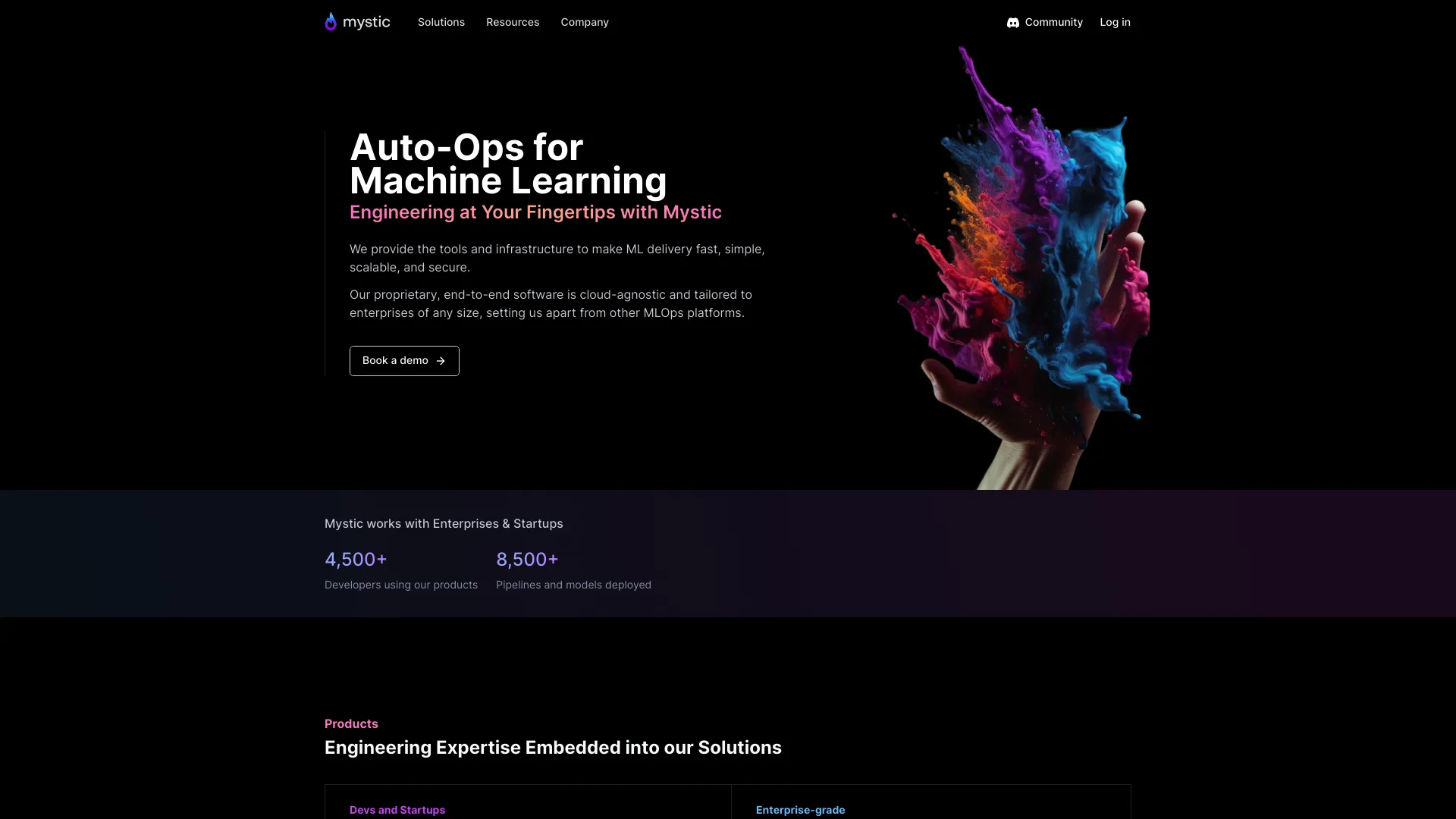
MysticAI
AI Mlops Platform
Unleash the power of Mystic AI's AI MLOps platform for fast, scalable, and secure ML deployment.
This tool is no longer approved.
Dang.ai no longer lists MysticAI as an active tool. It was marked inactive on Dec 23, 2024. It may have shut down, been acquired, or otherwise become unavailable.
What does MysticAI do?
What is mystic.ai?
Mystic.ai is a platform simplifying the deployment and scaling of machine learning models. Offering serverless deployment on a shared cluster with pay-per-second pricing starting from $0.1/h, it manages tasks like scaling, caching, GPU sharing, and spot instance management. Additionally, it provides an enterprise solution for running AI models within users' own infrastructure, leveraging serverless GPU inference. With access to a variety of community-built ML models, Mystic.ai serves as an accessible gateway to AI for users at all levels of expertise.
What kind of models can I deploy on Mystic.ai?
Mystic.ai simplifies the deployment and scalability of machine learning models. Users can choose from various deployment options: 1.
- **Serverless Deployment:** Models can be run on Mystic.ai's shared cluster, with payment based on inference time (starting from $0.1/h). This option is ideal for quick setup and effortless scaling without the need to manage infrastructure.
3.
- **Enterprise Solution (Bring Your Own Cloud - BYOC):** For those preferring to utilize their own infrastructure, Mystic.ai offers an enterprise solution. Users can deploy AI models as APIs within their chosen cloud or infrastructure. This option harnesses serverless GPU inference for ML models, ensuring seamless deployment and scaling on advanced NVIDIA GPUs while providing maximum privacy and control over scaling.
5.
- **Recommended Models:** Mystic.ai suggests several models for specific tasks. Collaborative Filtering or Matrix Factorization models are suitable for recommending items based on user behavior and historical data. For Speech Recognition, DeepSpeech or Listen, Attend, and Spell (LAS) models are recommended.
How much does mystic.ai cost?
Mystic.ai presents two distinct pricing models: 1.
- **Serverless Deployment:** Users are charged solely for the inference time without incurring additional costs such as account fees, egress fees, or storage fees. The pricing details for serverless GPU options are as follows:
- - Nvidia A100 (40GB): $0.000833/s or $3/h.
- - Nvidia A100 (80GB): $0.001111/s or $4/h.
- - Nvidia T4 (16GB): $0.000111/s or $0.4/h.
- - Nvidia L4 (24GB): $0.000208/s or $0.75/h.
- - GPU Fractionization options include:
- - Nvidia A100 (5GB): $0.000119/s or $0.429/h.
- - Nvidia A100 (10GB): $0.000278/s or $1/h.
- - Nvidia A100 (20GB): $0.000417/s or $1.5/h.
- Additionally, users can commence their usage with $20 free credits, and no credit card information is required.
12.
- **Bring Your Own Cloud (BYOC):** Users can opt for a flat monthly fee to utilize their cloud compute credits in conjunction with Mystic.ai's software. This model offers independence from scaling considerations and provides control over scaling responsiveness, enabling users to scale down to zero. Notably, no prior DevOps or Kubernetes experience is necessary, and users can deploy the latest models from the explore page with just one click. Moreover, Mystic.ai offers a money-back guarantee within the initial 30 days if users are dissatisfied with the BYOC service.
What are the benefits of mystic.ai?
Mystic.ai offers numerous advantages for deploying and scaling machine learning models: 1.
- **Serverless Deployment:** Users can run models on Mystic.ai's shared cluster, paying solely for inference time. This approach is cost-effective and hassle-free, making it ideal for swift deployment without infrastructure concerns.
3.
- **Enterprise Solution (BYOC):** With this option, users deploy AI models as APIs within their own cloud or infrastructure, utilizing serverless GPU inference for ML models. This facilitates effortless deployment and scaling on advanced NVIDIA GPUs while ensuring maximum privacy and control over scaling.
5.
- **Community-Built Models:** Mystic.ai enables users to explore and utilize a diverse range of community-built ML models. This feature not only expands model options but also helps users become familiar with the deployment platform and its functionalities.
In conclusion, Mystic.ai streamlines model deployment, whether users opt for Mystic.ai's cloud or their own infrastructure.
What are the limitations of mystic.ai?
While Mystic.ai offers several advantages for deploying and scaling machine learning models, it's essential to consider some limitations: **Technical Limitations:**
- **Interpretability:** Understanding the decision-making process of AI models can be challenging due to their complexity. Mystic.ai may encounter difficulties in providing clear explanations for its algorithmic choices.
- **Data Availability:** The effectiveness of AI models heavily relies on the availability of high-quality data. Limited access to relevant data can hinder the performance of deployed models.
**Practical Limitations:**
- **Cloud Dependency:** Despite providing serverless deployment, Mystic.ai relies on cloud infrastructure. Users may face constraints if they intend to deploy models outside the ecosystem of specific cloud providers.
- **Resource Constraints:** Deploying large-scale models with significant computational requirements may be restricted by available resources and associated costs.
- **Evolution of Techniques:** The field of AI is continuously evolving, with new techniques emerging regularly. Mystic.ai must stay abreast of these advancements to remain competitive and relevant.
Despite these limitations, Mystic.ai streamlines model deployment and offers unique features such as serverless GPU inference, enhancing accessibility and efficiency in deploying machine learning models.
How does MysticAI optimize AI model deployment costs?
MysticAI optimizes AI model deployment costs by allowing models to run on spot instances and enabling GPU fractionalization. This means that multiple models can operate on a single GPU, such as A30, A100, or H100, without any code alterations. Moreover, MysticAI's auto-scaler can reduce GPU usage to zero if models stop receiving requests, thus conserving resources. Users can also leverage their existing cloud credits and agreements to offset costs while using MysticAI.
What are the deployment options available with MysticAI?
MysticAI offers two main deployment options: deploying in your own cloud (Azure/AWS/GCP) or using MysticAI's shared GPU cluster. Deploying in your own cloud allows for full scalability and cost efficiency, with all MysticAI features integrated. The shared cloud deployment provides a low-cost option, although performance may vary based on real-time GPU availability. Both options ensure fast inference and low cold-start times through advanced techniques like custom container registries built in Rust.
How does MysticAI ensure high performance in AI model deployment?
MysticAI ensures high performance in AI model deployment by utilizing advanced inference engines like vLLM, TensorRT, and TGI. The platform's scheduler quickly determines the optimal queuing, routing, and scaling strategy within milliseconds. MysticAI's custom container registry, written in Rust, offers significantly lower cold-starts, enabling fast loading of AI models. The platform’s fully managed Kubernetes environment and comprehensive API, CLI, and Python SDK simplify the deployment process, ensuring seamless and efficient AI inference.