Private LLM
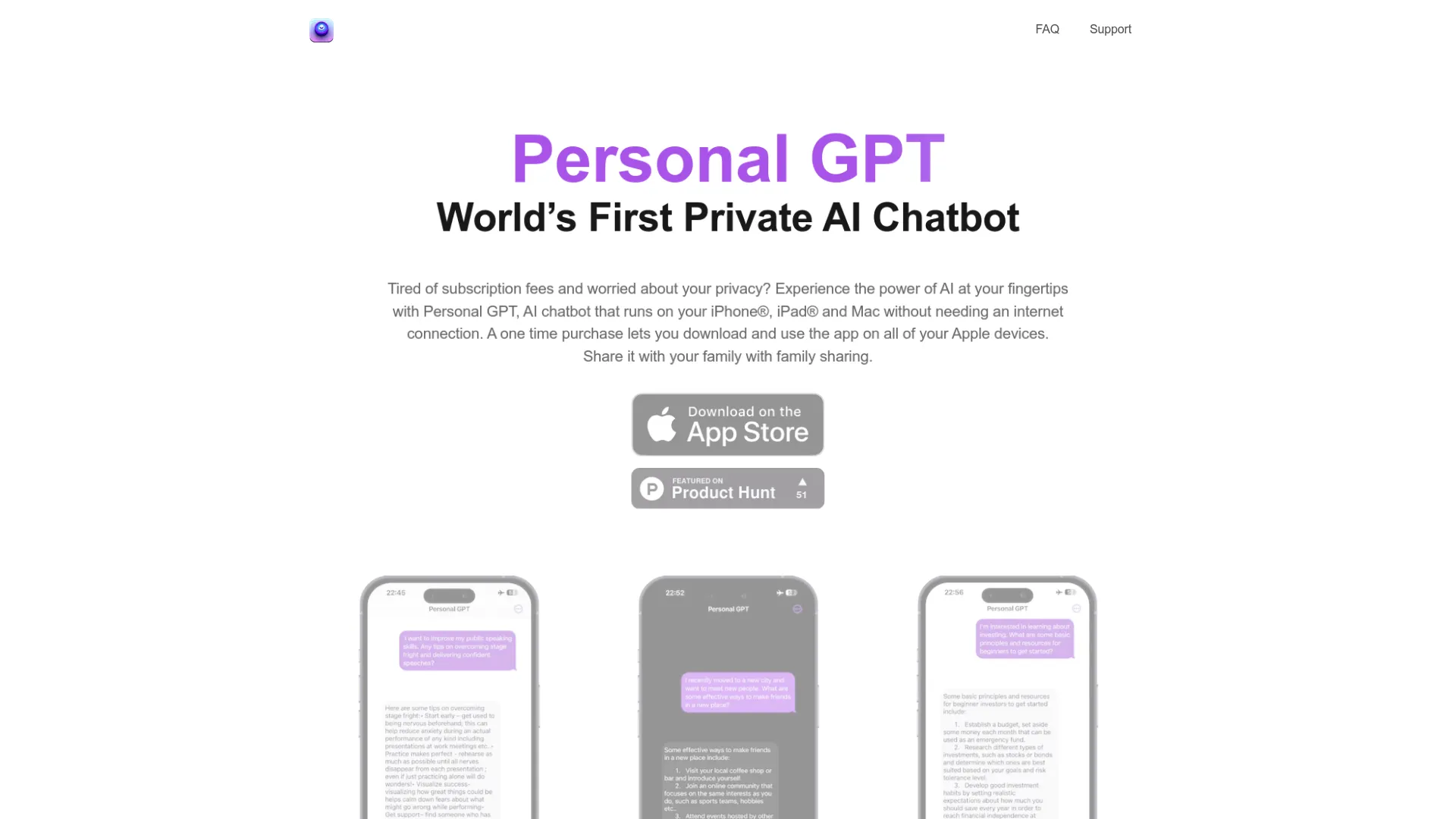
AI Chatbot For Ios And Macos Devices With Privacy And Convenience
Unparalleled privacy and convenience: Personal GPT - the AI chatbot for iOS and macOS devices.
What does Private LLM do?
How private is Private LLM and does it require internet?
Private LLM runs entirely on-device on iPhone, iPad, and Mac. It operates offline, and your data never leaves your device—there’s no cloud, no tracking, and no logins required. You can use it anytime, anywhere, without an internet connection.
Which devices and platforms does Private LLM support?
Private LLM is available on iPhone, iPad, and Mac (iOS, iPadOS, and macOS). It runs offline on-device across these Apple platforms, with a single purchase unlocking use on all supported devices.
What open-source models does Private LLM support and how does model availability depend on your device?
Private LLM supports a broad range of open-source LLM families, including Llama 3.x, Google Gemma, Mixtral, Phi, Qwen, and DeepSeek R1 Distill, among others. Model availability is organized by device RAM, so the exact models you can run depend on your device’s memory (e.g., 6GB+ RAM, 8GB+ RAM, 16GB+ RAM for iOS devices; 8GB+, 16GB+, 24GB+ RAM tiers for macOS). This allows you to choose models that fit your device while keeping everything on-device.
How can I automate Private LLM with Siri, Shortcuts, and x-callback-url?
Private LLM integrates with Siri and Apple Shortcuts to create AI-powered workflows without coding. It also supports the x-callback-url standard, enabling seamless automation with many iOS and macOS apps.
Do I need a subscription or ongoing fees?
No. Private LLM uses a one-time purchase model that unlocks the app across all Apple platforms (iPhone, iPad, and Mac) and includes Family Sharing for up to six relatives. There are no subscription fees.
What languages does Private LLM support for writing and editing?
Private LLM offers AI Language Services that support multiple languages, including English and select Western European languages, for tasks like grammar correction, summarization, translation, and text enhancement.
How can I get help if I run into issues?
If you need assistance, use the Help options on the site. Provide your name, email, and a description of your issue, and select the category that fits (General Inquiry, Technical Issue or Bug Report, or Feedback). The support team will respond as soon as possible.
How are updates and new models delivered?
Updates and new models are documented in Release Notes. Check the Release Notes to learn about improvements, new models, and performance enhancements.
What makes Private LLM fast and high-quality on-device?
Private LLM uses OmniQuant quantization with a learnable weight clipping mechanism, paired with optimized Metal kernels. This combination helps deliver fast, high-quality on-device text generation and avoids common drawbacks of other quantization methods that don’t handle outlier weights well.